Using Gemini API for the Semantic Web
There’s been a lot of excitement about large language models, and I’ve been largely underimpressed by a constant stream of chatbots that just tell you what you want to hear. I expect more from AI than that. I want it to help do tasks for me, and to make sense of the digital world to make my life more zen.
I recently learned about Gemini’s structured output API. Rather than responding to your multimodal prompt with a bunch of plain text, it can return a JSON payload based on an input schema.
So I can make a Gemini convert an unstructured input to a structured input and use that as the basis of better programs.
For instance, I read a lot. I’ve read 28 books since the start of the year. I track my reading through Goodreads, which no longer has an API. I also am a regular user of the New York Public Library, which also does not have an API. I would like a system that takes my to-read books from Goodreads and requests them from the library.
To do this, I will want to define a standard format to represent books on both Goodreads and NYPL. Beyond books, I want the LLM to be able to make sense of anything in a structured way.
So I turned to schema.org, a project that started a while back to help define the semantic web. These types are already used across the web and provide a common vocabulary for all kinds of objects, including Book.
I can easily pull all the existing schemas from a single JSON file in their GitHub repository. This format is JSON, although it uses a bunch of links and attributes to represent every attribute or type:
{
"@id": "schema:illustrator",
"@type": "rdf:Property",
"rdfs:comment": "The illustrator of the book.",
"rdfs:label": "illustrator",
"schema:domainIncludes": {
"@id": "schema:Book"
},
"schema:rangeIncludes": {
"@id": "schema:Person"
}
},{
"@id": "schema:Book",
"@type": "rdfs:Class",
"rdfs:comment": "A book.",
"rdfs:label": "Book",
"rdfs:subClassOf": {
"@id": "schema:CreativeWork"
}
},That’s not especially helpful, since I need to convert that into more of a standard JSON schema format in order to provide that in the Gemini API requirements.
So I started by writing a short script that would process the file.
const schemas = require('../src/schemaorg-jsonld.json')
const graph = schemas['@graph']
const geminiGraph: Record<string, Schema> = {}
const possibleTypes: string[] = []
const simpleDataTypes = {
'schema:Text': SchemaType.STRING,
'schema:URL': SchemaType.STRING,
'schema:Boolean': SchemaType.BOOLEAN,
'schema:Number': SchemaType.NUMBER,
'schema:Integer': SchemaType.INTEGER,
'schema:Time': SchemaType.STRING, // Timestring
'schema:DateTime': SchemaType.STRING, // Timestring
'schema:Date': SchemaType.STRING, // Timestring
}
// First pass creates an entry for each thing in the graph
for (const property of graph) {
const id = property['@id']
if (simpleDataTypes[id]) {
geminiGraph[id] = {
type: simpleDataTypes[id],
description: property['rdfs:comment'] || property['rdfs:label'] || "",
}
continue
}
geminiGraph[id] = {
type: simpleDataTypes[property['@type']] ?? SchemaType.OBJECT,
description: property['rdfs:comment'] || property['rdfs:label'] || "",
}
// Do this now to begin the process of memory mapping
if (!simpleDataTypes[property['@type']]) {
geminiGraph[id].properties = {}
}
if (property['rdfs:subClassOf']) {
if (property['rdfs:subClassOf']['@id'] === 'schema:Enumeration') {
// This is an enum
geminiGraph[property['@id']].type = SchemaType.STRING
geminiGraph[property['@id']].enum = []
continue
}
}
}
// Next pass attaches entries in the graph
for (const property of graph) {
if (geminiGraph[property['@id']].type !== 'object') {
continue
}
const potentialTypes: string[] = (() => {
const sp = property['schema:rangeIncludes']
if (sp === undefined) return [0] // DataType
if (Array.isArray(sp)) {
return sp.map(x => x['@id'])
}
return Object.values(sp)
})()
const type = potentialTypes[0]
// for (const type of potentialTypes) {
const id = (() => {
const origId = property['@id']
if (potentialTypes.length === 1) {
return origId
}
// return `${origId}_${type}`
return `${origId}`
})()
geminiGraph[id] = {...geminiGraph[property['@id']]}
if (property['schema:rangeIncludes']) {
const ref = simpleDataTypes[type] ?
{ type: simpleDataTypes[type] } :
geminiGraph[type]
if (geminiGraph[id].properties) {
geminiGraph[id].properties![type] = ref
} else {
geminiGraph[id].properties = {
[type]: ref
}
}
}
const superProperties: string[] = (() => {
const sp = property['schema:domainIncludes']
if (sp === undefined) return []
if (Array.isArray(sp)) {
return sp.map(x => x['@id'])
}
return Object.values(sp)
})()
for (const superProperty of superProperties) {
if (!geminiGraph[superProperty].properties) {
geminiGraph[superProperty]!.properties = {
[id]: geminiGraph[id]
}
} else {
geminiGraph[superProperty]!.properties![id] = geminiGraph[id]
}
}
// }
}
// Do an enum pass
for (const property of graph) {
const ptype = property['@type']
if (geminiGraph[ptype]?.enum !== undefined) {
geminiGraph[ptype].enum?.push(property['rdfs:label'])
}
}
function subclassPass(property: any) {
const log = false
const subClassOf = (() => {
const sp = property['rdfs:subClassOf']
if (sp === undefined) return []
if (Array.isArray(sp)) {
return sp.map(x => x['@id'])
}
return Object.values(sp)
})()
if (log) { console.log('sarr', subClassOf) }
for (const sco of subClassOf) {
if (log) { console.log(sco) }
if (log) { console.log(geminiGraph[sco]) }
if (sco === 'schema:Enumeration') return
if (!geminiGraph[sco]) continue
const graphSco = graph.find(x => x['@id'] === sco)
if (graphSco['rdfs:subClassOf']) {
if (log) { console.log('scp', sco) }
subclassPass(graphSco)
}
const superclass = geminiGraph[sco]
if (!superclass || !superclass.properties) continue
if (!geminiGraph[property['@id']].properties) {
geminiGraph[property['@id']].properties = {}
}
for (const [k, v] of Object.entries<Schema>(superclass.properties ?? {})) {
const pid = property['@id']
if (log) { console.log('kv', k) }
geminiGraph[pid]!.properties![k] = v
}
}
}
// Do a subclass pass
for (const property of graph) {
if (!property['rdfs:subClassOf']) continue
subclassPass(property)
}
const schema = 'schema:Book'
const jsonout = geminiGraph[schema]
console.log(JSON.stringify(jsonout))It took a bit of work and iteration to get to this point, using memory references to make sure that order didn’t matter. And I had to do one iteration at the end to get the enums to work properly. It’s admittedly not the most efficient script, but I only need to do this one time as a pre-processor to convert all of the types. Then I can use those when running in production.
Running the script bit-by-bit, it works. When I try to run JSON.stringify, I get an unexpected error. It talks about circular references. What’s going on.
The problem with schema.org types is that they’re way too flexible and strongly-typed. This is great in some ways, but makes serialization a problem.
If you take a look at the Book type, you see attributes like Boolean abridged and Text isbn. It inherits properties of the CreativeWork type such as Number copyrightYear and properties of the Thing type like Text name. This also means it brings in a lot of attributes that are not high priority like Text interactivityType. That results in a highly verbose type, but those types could be ignored and aren’t a big deal.
The bigger problem is that a book has an attribute called Person illustrator, which points to a canonical Person type. This person type has an attribute Person children. When a Person is a descendent of Person, it leads to infinite recursion if you try to serialize the entire structure. That’s quite bad.
Unfortunately, there’s also not quite a good way to resolve this. I threw a lot of ideas into it.
For one attempt, I tried hard-coding a lot of types to be a string. Because while it’s nice that my book has a Person illustrator, that means I could end up storing the illustrator’s children, their deathPlace, their deathPlace's review, their deathPlace's review's copyrightHolder, and so on.
const simpleDataTypes = {
'schema:Text': SchemaType.STRING,
'schema:URL': SchemaType.STRING,
'schema:Boolean': SchemaType.BOOLEAN,
'schema:Number': SchemaType.NUMBER,
'schema:Integer': SchemaType.INTEGER,
'schema:Time': SchemaType.STRING, // Timestring
'schema:DateTime': SchemaType.STRING, // Timestring
'schema:Date': SchemaType.STRING, // Timestring
'schema:ListItem': SchemaType.STRING, // Workaround
'schema:DefinedTerm': SchemaType.STRING, // Workaround
'schema:Taxon': SchemaType.STRING, // Workaround
'schema:BioChemEntity': SchemaType.STRING, // Workaround
'schema:DefinedTermSet': SchemaType.STRING, // Workaround
'schema:ImageObject': SchemaType.STRING, // Workaround
'schema:MediaObject': SchemaType.STRING, // Workaround
'schema:TextObject': SchemaType.STRING, // Workaround
'schema:VideoObject': SchemaType.STRING, // Workaround
'schema:AudioObject': SchemaType.STRING, // Workaround
'schema:Language': SchemaType.STRING, // Workaround
'schema:QuantitativeValue': SchemaType.NUMBER, // Workaround
'schema:AboutPage': SchemaType.STRING, // Workaround
'schema:Audience': SchemaType.STRING, // Workaround
'schema:Claim': SchemaType.STRING, // Workaround
'schema:Comment': SchemaType.STRING, // Workaround
'schema:bioChemInteraction': SchemaType.STRING, // Workaround
'schema:bioChemSimilarity': SchemaType.STRING, // Workaround
'schema:hasBioChemEntityPart': SchemaType.STRING, // Workaround
'schema:softwareAddOn': SchemaType.STRING, // Workaround
'schema:worksFor': SchemaType.STRING, // Workaround
'schema:parents': SchemaType.STRING, // Workaround
'schema:advanceBookingRequirement': SchemaType.STRING, // Workaround
'schema:potentialAction': SchemaType.STRING, // Workaround
'schema:publisherImprint': SchemaType.STRING, // Workaround
'schema:subjectOf': SchemaType.STRING, // Workaround
'schema:offeredBy': SchemaType.STRING, // Workaround
'schema:interactionType': SchemaType.STRING, // Workaround
'schema:address': SchemaType.STRING, // Workaround
'schema:spatial': SchemaType.STRING, // Workaround
'schema:geoTouches': SchemaType.STRING, // Workaround
'schema:sourceOrganization': SchemaType.STRING, // Workaround
'schema:mainEntityOfPage': SchemaType.STRING, // Workaround
'schema:isBasedOnUrl': SchemaType.STRING, // Workaround
'schema:servicePostalAddress': SchemaType.STRING, // Workaround
'schema:publishedOn': SchemaType.STRING, // Workaround
'schema:diversityStaffingReport': SchemaType.STRING, // Workaround
'schema:archivedAt': SchemaType.STRING, // Workaround
'schema:publishingPrinciples': SchemaType.STRING, // Workaround
'schema:occupationLocation': SchemaType.STRING, // Workaround
'schema:educationRequirements': SchemaType.STRING, // Workaround
'schema:performerIn': SchemaType.STRING, // Workaround
'schema:correctionsPolicy': SchemaType.STRING, // Workaround
'schema:hostingOrganization': SchemaType.STRING, // Workaround
'schema:composer': SchemaType.STRING, // Workaround
'schema:funding': SchemaType.STRING, // Workaround
'schema:recordedAt': SchemaType.STRING, // Workaround
'schema:material': SchemaType.STRING, // Workaround
'schema:license': SchemaType.STRING, // Workaround
'schema:usageInfo': SchemaType.STRING, // Workaround
'schema:producer': SchemaType.STRING, // Workaround
'schema:countryOfOrigin': SchemaType.STRING, // Workaround
'schema:exampleOfWork': SchemaType.STRING, // Workaround
'schema:workExample': SchemaType.STRING, // Workaround
'schema:hasCertification': SchemaType.STRING, // Workaround
'schema:hasCredential': SchemaType.STRING, // Workaround
'schema:containedIn': SchemaType.STRING, // Workaround
'schema:department': SchemaType.STRING, // Workaround
'schema:makesOffer': SchemaType.STRING, // Workaround
'schema:translationOfWork': SchemaType.STRING, // Workaround
'schema:serviceSmsNumber': SchemaType.STRING, // Workaround
'schema:subEvent': SchemaType.STRING, // Workaround
'schema:eventSchedule': SchemaType.STRING, // Workaround
'schema:shippingOrigin': SchemaType.STRING, // Workaround
'schema:validForMemberTier': SchemaType.STRING, // Workaround
'schema:openingHoursSpecification': SchemaType.STRING, // Workaround
'schema:geoCrosses': SchemaType.STRING, // Workaround
'schema:contributor': SchemaType.STRING, // Workaround
'schema:accountablePerson': SchemaType.STRING, // Workaround
'schema:affiliation': SchemaType.STRING, // Workaround
'schema:funder': SchemaType.STRING, // Workaround
'schema:alumniOf': SchemaType.STRING, // Workaround
'schema:brand': SchemaType.STRING, // Workaround
'schema:memberOf': SchemaType.STRING, // Workaround
'schema:recordedIn': SchemaType.STRING, // Workaround
'schema:deathPlace': SchemaType.STRING, // Workaround
'schema:homeLocation': SchemaType.STRING, // Workaround
'schema:workLocation': SchemaType.STRING, // Workaround
'schema:locationCreated': SchemaType.STRING, // Workaround
'schema:spatialCoverage': SchemaType.STRING, // Workaround
'schema:attendee': SchemaType.STRING, // Workaround
'schema:workFeatured': SchemaType.STRING, // Workaround
'schema:workPerformed': SchemaType.STRING, // Workaround
'schema:itemOffered': SchemaType.STRING, // Workaround
'schema:availableAtOrFrom': SchemaType.STRING, // Workaround
'schema:parentOrganization': SchemaType.STRING, // Workaround
'schema:manufacturer': SchemaType.STRING, // Workaround
'schema:isRelatedTo': SchemaType.STRING, // Workaround
'schema:birthPlace': SchemaType.STRING, // Workaround
'schema:character': SchemaType.STRING, // Workaround
'schema:illustrator': SchemaType.STRING, // Workaround
'schema:sponsor': SchemaType.STRING, // Workaround
'schema:author': SchemaType.STRING, // Workaround
'schema:creator': SchemaType.STRING, // Workaround
'schema:editor': SchemaType.STRING, // Workaround
'schema:maintainer': SchemaType.STRING, // Workaround
'schema:provider': SchemaType.STRING, // Workaround
'schema:translator': SchemaType.STRING, // Workaround
'schema:publisher': SchemaType.STRING, // Workaround
'schema:sdPublisher': SchemaType.STRING, // Workaround
'schema:seller': SchemaType.STRING, // Workaround
'schema:contentLocation': SchemaType.STRING, // Workaround
'schema:publishedBy': SchemaType.STRING, // Workaround
'schema:director': SchemaType.STRING, // Workaround
'schema:directors': SchemaType.STRING, // Workaround
'schema:attendees': SchemaType.STRING, // Workaround
'schema:founder': SchemaType.STRING, // Workaround
'schema:members': SchemaType.STRING, // Workaround
'schema:actor': SchemaType.STRING, // Workaround
'schema:actors': SchemaType.STRING, // Workaround
'schema:organizer': SchemaType.STRING, // Workaround
'schema:copyrightHolder': SchemaType.STRING, // Workaround
'schema:musicBy': SchemaType.STRING, // Workaround
'schema:partOfEpisode': SchemaType.STRING, // Workaround
'schema:partOfSeason': SchemaType.STRING, // Workaround
'schema:partOfSeries': SchemaType.STRING, // Workaround
'schema:productionCompany': SchemaType.STRING, // Workaround
'schema:performer': SchemaType.STRING, // Workaround
'schema:performers': SchemaType.STRING, // Workaround
'schema:eligibleTransactionVolume': SchemaType.STRING, // Workaround
'schema:superEvent': SchemaType.STRING, // Workaround
'schema:subEvents': SchemaType.STRING, // Workaround
'schema:video': SchemaType.STRING, // Workaround
'schema:workTranslation': SchemaType.STRING, // Workaround
'schema:isPartOf': SchemaType.STRING, // Workaround
'schema:hasPart': SchemaType.STRING, // Workaround
'schema:isVariantOf': SchemaType.STRING, // Workaround
'schema:isSimilarTo': SchemaType.STRING, // Workaround
'schema:isAccessoryOrSparePartFor': SchemaType.STRING, // Workaround
'schema:predecessorOf': SchemaType.STRING, // Workaround
'schema:successorOf': SchemaType.STRING, // Workaround
'schema:model': SchemaType.STRING, // Workaround
'schema:isConsumableFor': SchemaType.STRING, // Workaround
'schema:sdLicense': SchemaType.STRING, // Workaround
'schema:warranty': SchemaType.STRING, // Workaround
'schema:hasProductReturnPolicy': SchemaType.STRING, // Workaround
'schema:hasMerchantReturnPolicy': SchemaType.STRING, // Workaround
'schema:mentions': SchemaType.STRING, // Workaround
'schema:educationalAlignment': SchemaType.STRING, // Workaround
'schema:about': SchemaType.STRING, // Workaround
'schema:mainEntity': SchemaType.STRING, // Workaround
'schema:additionalProperty': SchemaType.STRING, // Workaround
'schema:interactionStatistic': SchemaType.NUMBER, // Workaround
}It ended up getting quite a bit out of hand, as I kept finding more fields that needed to be forced to a string rather than the rich type.
Unfortunately, even all this work was insufficient at reaching something that was reasonable. Having so many rich schema types leads to this ongoing battle to figure out where the next circular reference comes from.
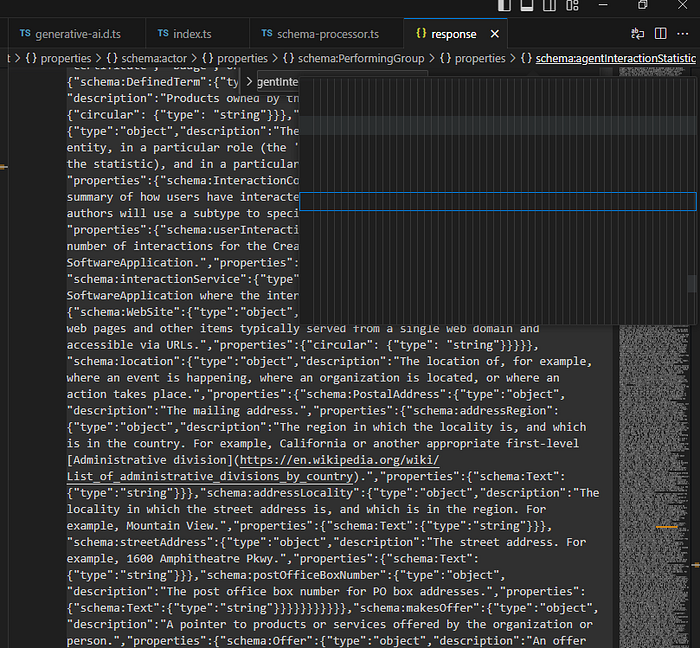
I tried a few libraries to try fixing the circular problem, and some attempts to cut off all circular references, but you still end up with a messy, long JSON blob that Gemini has trouble handling. This screenshot from AI Studio was after several hours where I decided to give up on this approach.
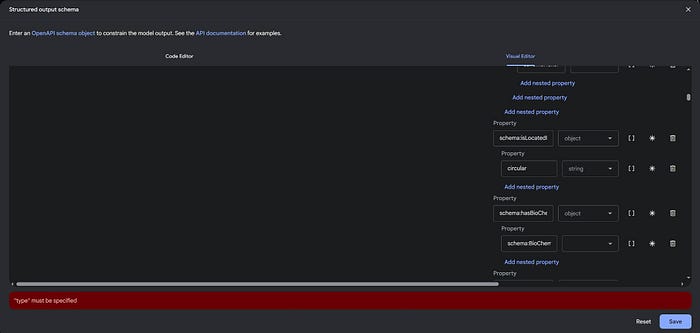
After a lot of struggling, I finally decided that my approach was fundamentally flawed. While I could use the Schema types and fields as an initial reference, I couldn’t use the types directly from their repository. I’d have to create them from scratch and ensure they are set up in a way to be serialized:
const simpleString = (description: string) => ({
type: SchemaType.STRING,
description,
})
const simpleBool = (description: string) => ({
type: SchemaType.BOOLEAN,
description,
})
schemaGraph['bookFormatType'] = simpleEnum('The publication format of the book.', [
'AudiobookFormat', 'EBook', 'GraphicNovel',
'Hardcover', 'Paperback',
])
schemaGraph['Book'] = {
type: SchemaType.OBJECT,
properties: {
...schemaGraph['creativeWork'].properties,
abridged: simpleBool('Indicates whether the book is an abridged edition.'),
bookEdition: simpleString('The edition of the book.'),
bookFormat: schemaGraph['bookFormatType'],
illustrator: simpleString('The illustrator of the book.'),
isbn: simpleString('The ISBN of the book.'),
numberOfPages: simpleInt('The number of pages in the book.'),
}
}Finally, I can take a screenshot from Goodreads and have Gemini properly turn that into a high-quality JSON object.
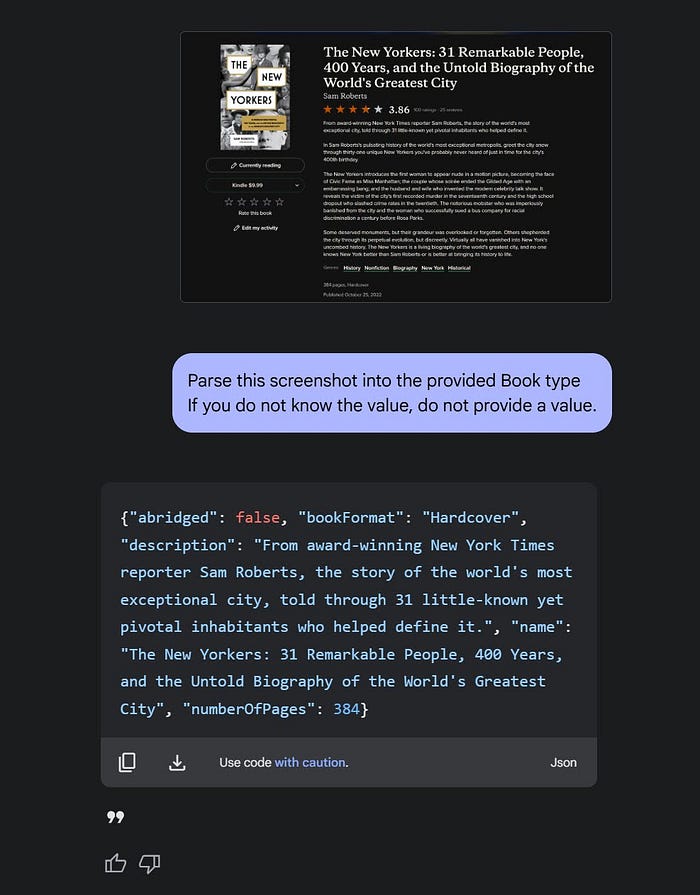
But I also need to go beyond that. I will need a first pass to take my input and fetch the underlying type of the object in the screenshot. It might not always be a Book. So I have to create an enum from all my title-case types and use that as an initial prompt.
const typeEnums = {
type: SchemaType.STRING,
description: 'The best possible type that best represents the input',
enum: Object.keys(schemaGraph).filter(x => {
const x0 = x.substring(0, 1)
return x0 === x0.toUpperCase()
})
}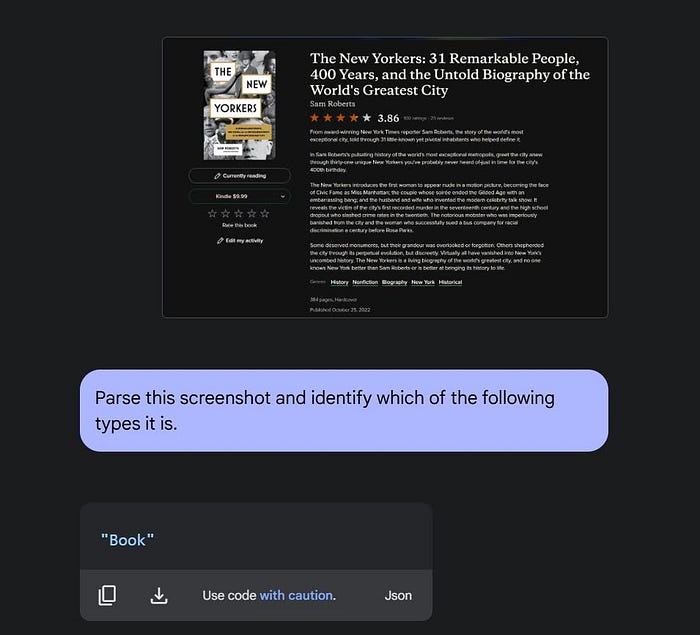
Since it properly identifies the screenshot as a Book, I can proceed with a second query that pulls in the Book schema and get the JSON output.
This initial post detailed my early work in using AI to start building up a renewed semantic web. Using LLMs to turn unstructured data into structured data allows me to make it easier to continue advancing my project. By standardizing on a limited set of standardized types, I can bring together different websites and make it easier to migrate data from one place to another.
I’ll have another post soon that follows up on this initial work and what I’ve learned.
